取得したデータの重複を削除して表示する
SQLでデータを取得した際に、重複しているデータを削除して表示したいことが度々あります。そんなときに役立つのが「GROUP BY句」または「DISTINCT」です。
例えば、学生表の「年」が1のデータは組が何組まであるのか調べたいとしましょう。
SELECT 組 FROM 学生 WHERE 年 = 1;
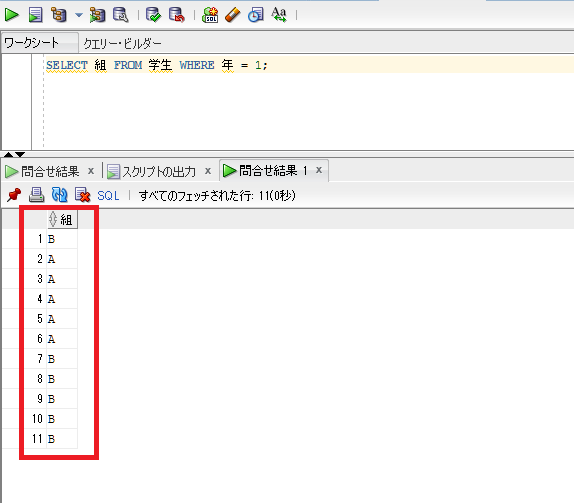
↑の結果では組が表示されていますが、同じ組が重複して表示されているため何組まであるかは自分で見て判断しなければいけません。それは非常に効率が悪いので、重複をなくして表示してみましょう。
GROUP BY句を使った重複の削除
GROUP BY句は列を指定することで、その列でデータをグループ化することができます。
GROUP BY句の使用方法は以下の通りです。
| SELECT 列名 FROM 表の名前 WHERE 列名 GROUP BY 列名; |
GROUP BY句はWHERE句の後、ORDER BY句の前に書かなくてはいけません。もちろんWEHRE句などがない場合はFROM句の後に書いてあれば大丈夫です。
SELECT 組 FROM 学生 WHERE 年 = 1 GROUP BY 組;
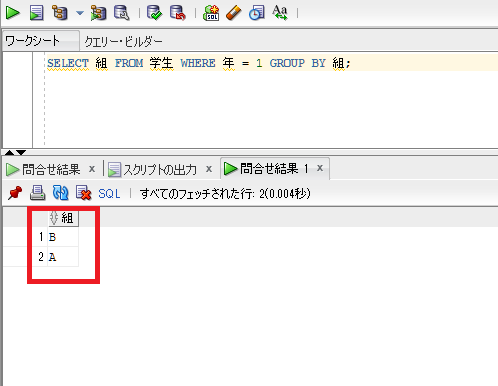
↑の結果を見ると、重複が削除され値が1つづつ表示されているのが分かります。
ここで注意点が1つ。GROUP BY句を使用した場合、SELECT句で指定できる列はGROUP BYで指定した列しか使えません。つまり、GROUP BYで学生表の組を指定した場合、SELECT句で組しか指定することができないのです。
GROUP BY句には複数の列を指定することもできます。その場合、指定した列の値の組み合わせによってグループ化され、表示されることになります。
SELECT 年,組 FROM 学生 GROUP BY 年,組;
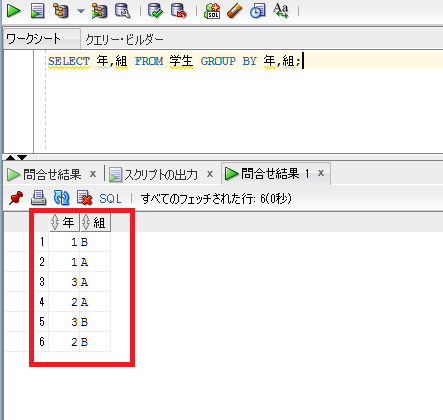
実はGROUP BY句は、重複を削除するために使うことはあまりありません。
データをグループ化して集計したり、平均値を出したりしたいときに使うことが多いです。
この集計・平均値を出すためにはグループ関数と言うものを使います。グループ関数に関しては別途記事にするつもりなので、今回はGROUP BY句の使い方を覚えるだけにしておきます。
DISTINCTを使った重複の削除
DISTINCTはGROUP BY句よりも簡単に重複を削除して、データを表示することができます。
| SELECT DISTINCT 列名 FROM 表の名前 WHERE 列名; |
使い方としては、SELECTの後、列名の前に「DISTINCT」と入れるだけです。
SELECT DISTINCT 組 FROM 学生 WHERE 年 = 1 ;
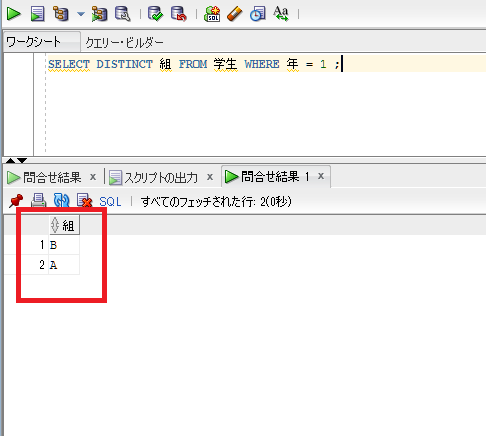
↑の結果を見ると、GROUP BY句と同じ結果になっているのが分かります。
また、SELECTで複数の列名を指定すると、GROUP BYと同じようにその列の値の組み合わせによって重複が削除されます。
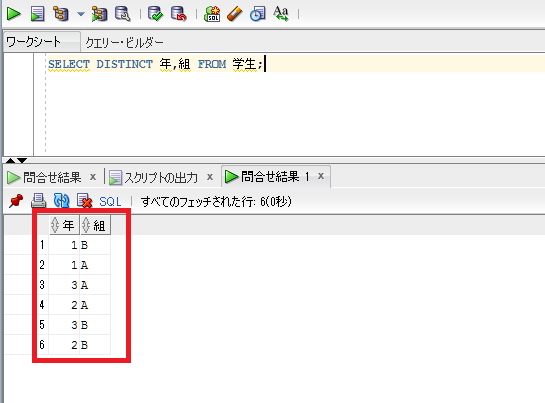
SELECT DISTINCT 年,組 FROM 学生;
重複の削除は、実際の開発でも使うことが多いのでしっかり覚えておきましょう。